The big picture
- Detection
- Build a network dedicated to the project … simple, small, using conv2D layers and so on …
- Get MNIST data, no need to extract project dedicated data
- Possibly pre-process the MNIST data
- Train network on MNIST data to build the weights
- Apply the model+weights to 6000×4000 image maps
- Geo location
- identify reference points in the 6000×4000 image maps
- geo-locate the detected unit against those reference points
- compute the latitude longitude
- Database
- identify labels in database
- fill the database
Frameworks
Darknet
- open source C code framework used by YOLO
- easy to run on google colaboratory
- how to build or configure the network?
- how to pre-process the MNIST data (eg.: to generate the .txt file with the box references…)?
- train the network: darknet detector train …
- test the network: darknet detector test …
- How to detect the overfit !!!
Keras
- open source Python framework with known API
- known API to build the network
- known API to embed MNIST data, no need for pre-processing
- known API to train the network, weights are embedded in the Python model network
- how to apply to 6000×4000 image maps?
- how to run on google colaboratory
What I’ve found so far …
Convenient functions for YOLO v4 based on AlexeyAB Darknet Yolo.
https://github.com/vincentgong7/VG_AlexeyAB_darknet
In this project, The author improved the YOLO by adding several convenient functions for detecting objects for research and the development community.
The added functions are implemented based on AlexeyAB version of Darknet. As it is updated frequently, hereby I publish a stable version of AlexeyAB Darknet Yolo with those convenient functions. This repo will also be updated regularly.
The detector function in AlexeyAB Darknet only supports a single image at a time. Therefore I added the batch function into this forked repo, which supports detecting images in a folder in one time. In the meantime, it exports information including the name of the image, the detected classes, the confidence and the bounding box coordinates in JSON and TXT files.
MNIST-Train Data For YOLO on GitHub (Darknet)
Process put in place
- provide network config file for Darknet
- take MNIST data
- resize MNIST data from 28×28 to 500×400 (PIL)
- generate traint.txt and test.txt files for Darknet
- train (or provide computed weights)
- Detect …
Result
This does not work for my project … why … it is always the same problem …
- The training images are 500×400 with an object filling the entire image.
- The candidate images are 416×416 with objects that are less than 40×40
- The gap between the “training object” sizes and the “to be detected object” sizes is far too big …
Next
- create an homogeneous environment between the training and the final detection … sizes must be of the same order of magnitude !!!
- training object 500×400 in training image 500×400 and detected object 40×40 in image 416×416 does NOT work. I tested it and lost my time !!!
- training object 40×40 in image 416×416 and detected object 40×40 in image 416×416 does NOT work !!! because the detected object is less than 10% the size of the image !!! I tested it and lost my time !!!
- training object 40×40 in image 256×256 and detected object 40×40 in image 256×256 SHOULD work !!! to be tested right now !!! see below …
What I did by myself !!!
Process
- For training data generation
- Python: split some images in 256×256 sub images
- Manual: annotate sub images with num objects and generate .txt files
- Google Colab
- train Yolov4 network on 10000 passes
- get weights
- Python: loop over candidate images
- split in 256×256 sub images (750 !!!)
- loop over sub images
- execute darknet detector test on sub images
get resulting boxes from txt and erase generated filesgenerate an aggregated box filedraw on original image- copy paste annotated sub images on blank big map to rebuild the full annotated map
Result
Have a zoom …
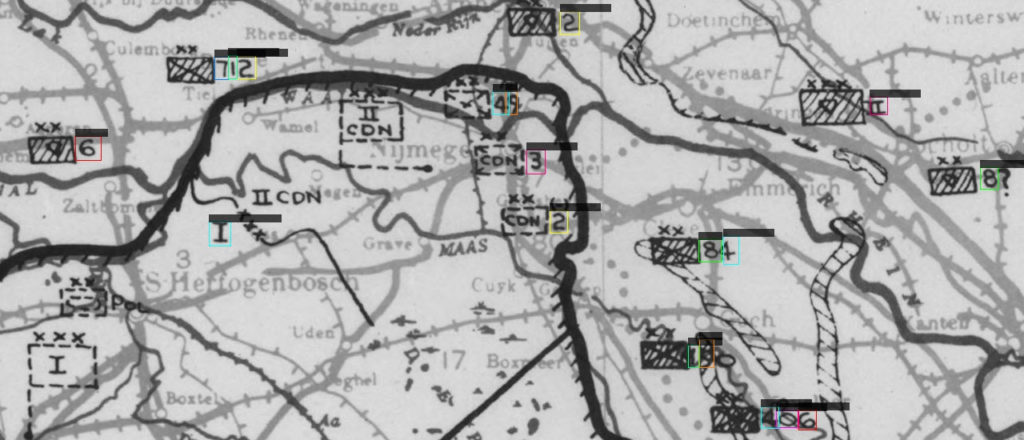
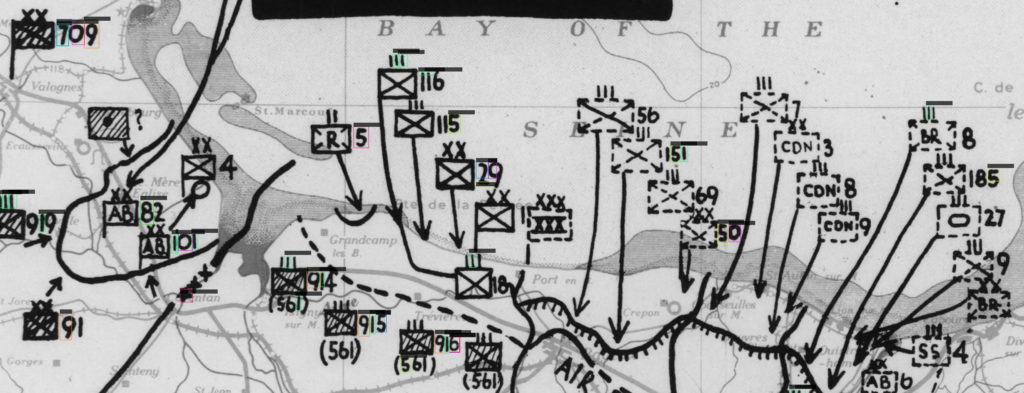
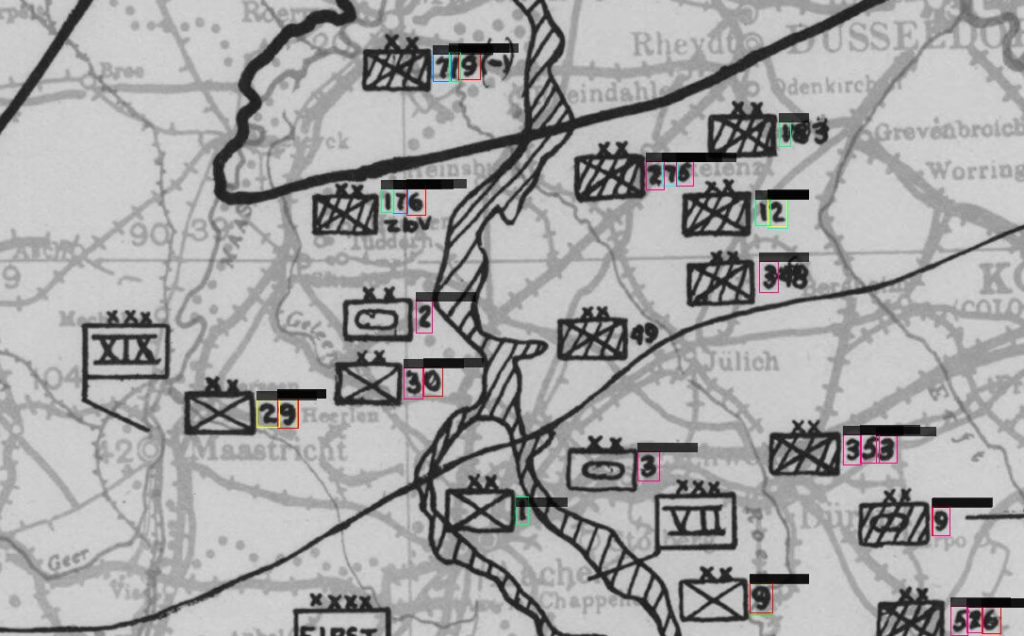
The test, even if not perfect, is good enough to keep this option for now. I see much less spurious detection, boxes are well located around the numbers and the identification is not so bad.
What I see is that I don’t have enough differentiated training objects … I’m pretty sure the maps where generated by more than one person … the handwritten characters differs and also the lighten of the maps … I collected the training objects from a single map … therefore …
The first picture shows very good results but is part of the training sequence
The second map clearly has a different look and feel … results are not so good
The third map is not from the training sequence but has the same look and feel as the first one, and then shows pretty good results
Next
- do not process the entire image when trying to detect the unit identification numbers !!! it is far too long !!!
- Instead, focus on locations where unit symbols have already been detected, the unit identification numbers are located at the right side of the unit symbol. This allow the maximum processing on the number detection.